Open Source Performance Monitoring Tool | Jamon
Filed under: performance monitoring, performance testing | Tags: jamon, java, javasimon, open-source, open-source performance monitoring, performance monitoring, spring, testing
 Comments (1)
Comments (1) Lot of times working with different performance testing projects, we sometimes feel that there is lack of simple but effective monitoring tool to work with. Even for the developers, there is no simple way to gauge the method execution times of their code directly. We have a tool from the open-source world Jamon that can help both developers and testers which can be installed and used without much of a fuss. Jamon has been in the market for some years now and frankly I stumbled on it only very recently.
This post is just to give an overview of the tool as there is good amount of case studies and examples available on the web. To show-case Jamon’s simplicity and capability, I have attached below a snapshot of what all it can monitor and how.
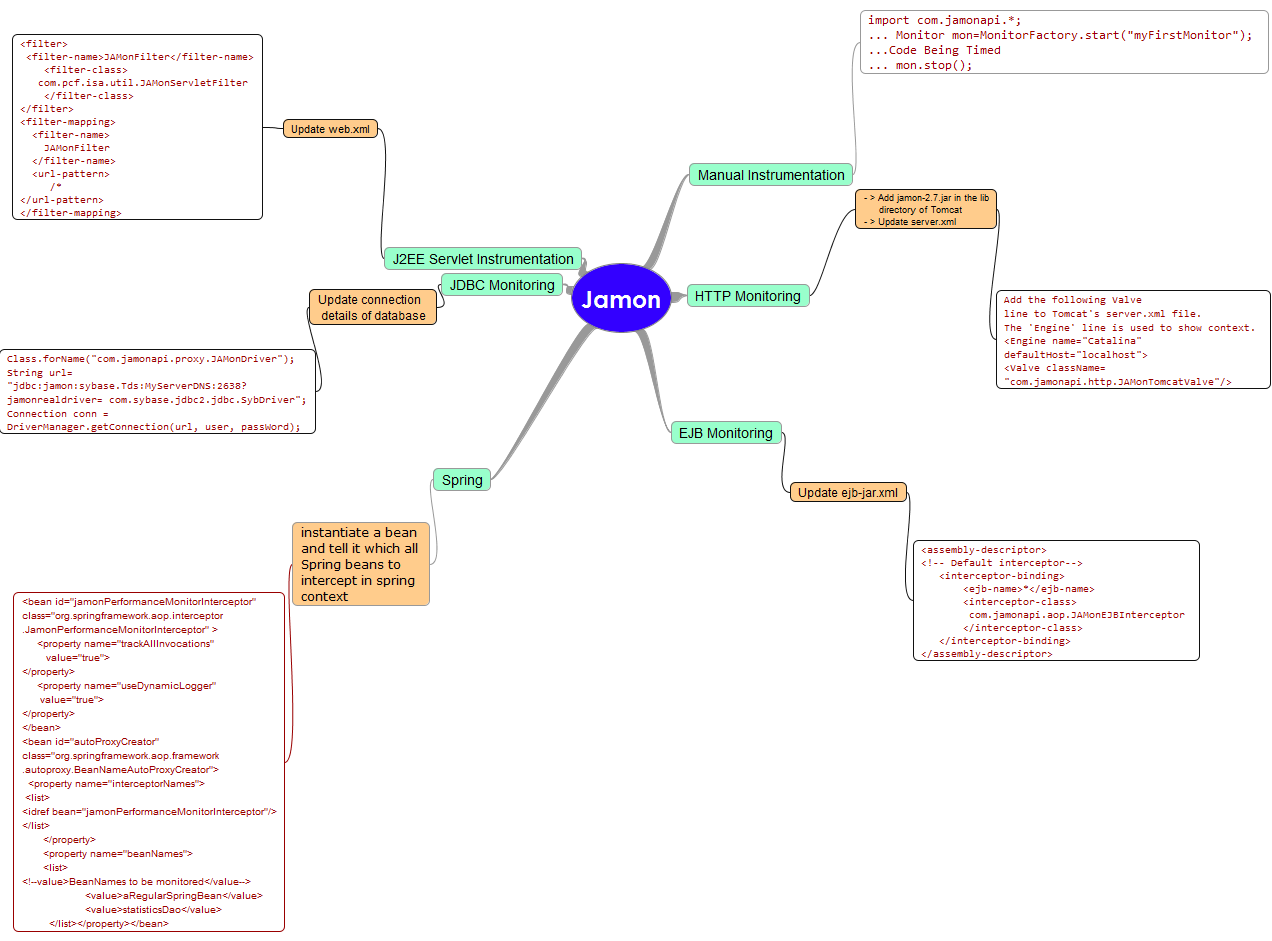
Jamon Implementation Approaches
It is a simple and effective tool in getting the method execution times without putting too much of monitoring code. This tool is most suited to web application developed in J2EE and Spring framework. It can also monitor in the following:
- Manual Instrumentation – Write explicit start and stop monitoring code – it is the only intrusive way
- HTTP Requests – server.xml only has to be updated to begin monitoring
- EJB – Update ejb-jar.xml to monitor EJBs
- JDBC – Connection string needs to be modified. Keeping connection string in configuration file would ensure no code change is needed.
- J2EE Servlet – Add a web filter in web.xml file.
- Spring Framework – Beans have to be updated in spring context.
Installation is fairly simple involving two steps:
- add JAMon.jar to your [WEBAPP_HOME]/web-inf/lib
- Deploy the jamon.war on your tomcat
Once the above steps are done, we can see the performance stats at http://localhost:8080/jamon/JAMonAdmin.jsp
Since the tool installation does not require any special privileges, even developers can include Jamon on their machines and check the performance of their own methods right during the development itself.
One of the other key feature is that it can easily enabled or disabled at the click of the button and anybody who has access to the dashboard and thus making its operation simple. I am not covering step-by-step usage of the tool as that is already available on the web. However, you can find the references that I used at the end of this post.
There is another tool JavaSimon from Google on the similar lines of Jamon. It has similar features and in some cases it also outscores Jamon. However, since there was many case studies available on the web, I preferred to use a tried and tested tool for my project.
So go ahead and give a shot to this beautiful tool and let me know your thoughts on this.
References
De-Mystifying Hadoop – Part 2
Filed under: big data, hadoop | Tags: bigdata, hadoop MapReduce, hdfs
Leave a Comment This is in continuation with an earlier post linked here.
At the heart of Hadoop is the Hadoop Distributed File System (HDFS) and MapReduce programming model. These two components form the crux of the Hadoop eco-system.
Hadoop Distributed File System (HDFS)
Definition – HDFS is is a distributed, highly fault-tolerant file system designed to run on low-cost commodity hardware. HDFS provides high-throughput access to application data and is suitable for applications with large data sets.
HDFS is the storage system to store large amount of data typically in terabytes and petabytes. It comprises of interconnected nodes where files and directories reside. A single HDFS cluster will have one node known as the NameNode that manages the filesystem and keeps a check on other nodes which act as data nodes. The data is stored on the data nodes in blocks (default size is 64 Mb). Whenever data is written to one of the nodes, data is replicated to other nodes in pipeline mode.
The data sent from the client follows the Client – Data Node 1 – Data Node 2 – Data Node pipeline path. However, the Client will be notified immediately once the data is written to Data Node 1 irrespective of whether the data replication has been complete or not.
HDFS was designed to run on the assumption, that at any point one of the nodes can go down. This assumption drove HDFS to the need for a design with quick fault-detection and recovery and data replication, to ensure no loss of data.
HDFS work on the Write-Once-Read-Many access model. The raw data initially transferred to HDFS remains as-is and all the processing that gets done on the data is stored in separate files enabling any time re-look up of the golden copy of data.

MapReduce Programming Model
The name MapReduce comes from the two functions – Map() and Reduce() from functional programming. Map is a procedure that performs filtering and sorting of data while Reduce procedure performs the final summary operations to generate the result. This is where the actual code gets written and MapReduce is what makes Hadoop powerful. You can go on writing n number of Map-Reduce programs on the same dataset to generate different views. As the code is moved to data nodes, it ensures parallel execution without the developer needing to think about parallelism during development.
From a conceptual standpoint, there are three steps in MapReduce model
- Mapping
Data in the form of key-value pairs in passed in to the Map() method. Map method processes the key value pairr based on the type of data set and generates another set of key-value pairs. This happens on individual data node. The output key-value pairs are placed on a shared space in HDFS.
- Shuffling
The output key-value pairs from the mapping functions from different nodes are now sorted in this phase. This is the only hase when data is shared across nodes. So from a performance standpoint, this becomes the key to optimize for performance. There is a concept of Combiners, which is a mini-Reduce program that gets executed on that particular data node itself. Similarly there is concept of Partitioning in which all the similar Keys are partitioned into similar buckets. Both these concepts help in improving the performance of the MapReduce program.
- Reduce
All the key-values after shuffling is fed into the Reduce function to get the necessary solution. The Reducers may or may not reside on all data nodes though it is recommended to have them on every node. Importantly, users never marshal the information between the data nodes. This marshaling is done within the Hadoop platform guided implicitly by the different keys associated with values.
References:
- http://hadoop.apache.org/docs/r0.18.0/hdfs_design.pdf
- http://www.ibm.com/developerworks/library/wa-introhdfs/
- http://en.wikipedia.org/wiki/MapReduce
- http://www-01.ibm.com/software/data/infosphere/hadoop/mapreduce/
- http://courses.cs.washington.edu/courses/cse490h/11wi/CSE490H_files/mapr-design.pdf
PS: My objective of these posts is only to provide .the conceptual understanding of Hadoop as a whole and I am also in a learning phase. So do point out any inaccuracies so that I can improve my understanding. Believe, there will be two more posts to cover the remaining topics as each topics are exhaustive in themselves.
De-Mystifying Hadoop – Part 1
Filed under: big data, hadoop | Tags: big data, hadoop, introduction, part1, simplistic~view
Comments (3) There has been quite a buzz on big data and hadoop. Frankly, self had also taken initiative and try to readup stuff on the internet. Somehow, I never was able to put my mind and soul to learning the concepts. So then when a training came around, I jumped on to it.
Interestingly, after finishing the training lot of my colleagues came up to me asking about it as everyone had heard about it but nobody could actually elucidate. So my purpose is just to provide a simplistic view of hadoop, which can help anyone get started on it and can build their knowledge base from there.
I am not an expert here, but just sharing what I have understood. So here I am taking the plunge to demystify big data by putting in my two cents hoping it helps someone find their calling 🙂
Challenge
With the maturing of internet, the amount of data getting generated is humungous. Businesses want to tap this huge data source to improve their service offerings to their customers and make money from it. The challenge was the that the traditional databases were ill-equipped to handle huge amounts of data as they were never designed to handle such volumes of data in the first place. To add a bit more detail to the challenges –
- Fundamentals have still not changed – Disk Seek is still the slowest performing component in any software architecture.
Any new design or principle had to work around this problem. Traditionally, there will be business logic which will retrieve data as and when needed. However, when amount of data increased, disk speed would come out as the biggest bottleneck. Oracle had introduced memcache to reduce the issues.
Additionally there were ETL tools such as Informatica and Ab Initio. These tools focused on end of day processing and were very good at that. But these tools came up short when it came to online processing. So there’s the challenge – Design something that can process huge volumes of data and give near real-time information to businesses and customers.
- Rise of Unstructured Data
With the number of podcast and videos being shared, storing and making the unstructured data searchable became a necessity. There are more content creators in the world at present than it ever has been in the entire history of human beings. We needed applications that would help us find useful content from the cacophony of information. To put it simply, we need to filter information from the noise.
- Resiliency and Availability
There were too many instances when the a blackout caused issues in recovering the data to the original state. Importantly, blackouts/downtime cost money. There are high availability systems which needs 99.999% availability and even if it fails, it should be back up in seconds if not in minutes. Many critical systems do have availability in place, yet it normally comes at a high cost.
![]()
How does Hadoop does it?
Hadoop identifies the above three critical challenges and others that I might have missed to come up with a solution which is easier to implement and which is open-source. Now for the big paradigm shift that Hadoop brings which I really thinks makes all the difference.
All the earlier models focused on bringing the data to application server (code) to do the processing. Hadoop does it the other way around. It sends the code to all the data for processing. This enables parallel processing of the data without streaming any data.
The code size being very small and repeatable can be cached and sent to the servers hosting data. This relieves the developers from writing code keeping parallel processing in mind.
Another key improvement is that the servers having data do not need to be high end servers. They can be small servers with processing and memory just a little bit more than what we get in standard laptop. To put it in numbers a 16 G memory machine with an I5 processor should be sufficient to act as one of the nodes.
From my perspective this was the basis from which everything else evolved. However, this is just the beginning and there is a huge new world that hadoop has created.
PS: I had planned to cover entire Hadoop in one post. However, the increasing length of the post has changed my mind. Hopefully I can finish it in the second part itself.
I have not covered history of Hadoop as I wanted to focus on the concepts so that everyone can get started. However, I would really recommend reading the fascinating history of Haddop. Last but not the least I am thankful to Venkat Krishnan who imparted a very exhaustive but insightful training.
P.PS: Do post your feedback so that I can improve as needed.
Tips to Create High Performing Scripts in LoadRunner
Filed under: performance testing, Uncategorized | Tags: loadrunner, performance testing, scripting, software testing, testing, tips
Leave a Comment 
More often not when we are load testing, our focus is generally on optimizing the application code. However, are we sure the scripts we are scripting in LoadRunner are optimal and they are not contributing to latency? Here are few tips that can help in keeping the memory footprint of loadrunner less.
- Keep it simple
Like most things in life, try keeping the complexity of the scripts as simple as possible. Basic theme is to ensure minimal memory footprint. Ideally, a newbie should be able to understand the script without presence of any extensive comments. One method is to have one script corresponding to a single business process. This can become cumbersome when the number of business processes is more resulting in huge number of scripts. On the other hand if there a complex business process, it does make sense to break it down into multiple scripts.
- Pointers
How we love them when we understand them! In an ideal scenario, pointers should help in reducing the memory footprint. However, memory management is manual in C and we are never sure how the memory is being allocated. Best way of using a pointer is to avoid them as far as possible.
- Custom Code and Custom Functions
All our programming lives, we have been taught to make things automated so that we create an abstract layer that user understands and hide the complex code beneath it. Moreover, reusability has always been drummed into us from the time we started printing “Hello World!” Yet when we are load testing, each line of custom code or custom function adds precious CPU cycles to your load testing. Avoid them as far as possible.
- LoadRunner extended library & Parametrization feature
LoadRunner has extended C library in a big way. Use of these functions is recommended as these functions have been tested for speed and is reliable to a large extent. These functions help in reducing the custom code and thus help in reducing complex coding.
Parametrization – Like most tools, LoadRunner has extensive options for parameterization and if used creatively can result in very simple solutions for some complex problems that are generally faced.
- Reuse Variables
Try reusing the defined variables again and again. Loop counters are a prime example for this. The more variables defined, the more memory it will consume. Keeping variables local as far as possible can also help in minimizing the memory footprint. When declaring arrays, ensure the size is optimal. For example, if a name is supposed to take 20 characters, having an array of 30 characters will not impact much. However, if array size is set for 100 characters for the same, then it becomes a problem.
This is primarily for testing of web applications using loadrunner. Do share your thoughts and other options of improving the scripts in the comment section! Will be all ears for it or should I say eyes for it:)
Performance Center: A ground up view
Filed under: performance testing | Tags: business case, HP, loadrunner, performance center, performance testing
Leave a Comment To begin with I was a big fan of Performance Center. I always saw it as tool built on the lines of Quality Center and thought it great for businesses to go for a performance center. However when I first started using it doubts started creeping in. And my doubts were confirmed once I got to use it extensively. So given here are my observations:
- To start with Performance Center is simply a wrapper over LoadRunner. Whatever, Performance Center (PC) does from the browser, set of commands are fired to the machines that has controller to start the testing. The benefits are given below:
- No need for the user to log-in to a controller machine
- No need for the user to log-in to load generators.
- These are all true. But the catch is, to begin a new test, PC takes almost 5-15 min to connect to Controller and Load generator. So if a test is stopped and started again average of 20 mins of time is lost in connection to the servers. On the other hand, same task happens instantaneously on Controller.
- Additional infrastructure is needed to deploy the performance center on server class machines. If the performance center is not fast enough all the testing will be impacted because of this.
- HP LoadRunner always had the issue of controller crashing during a test. With the introduction of PC, complexity has increased and crashes have become more frequent.
- Additional man-power is also needed to manage performance center. Any organization which deploys PC will need PC administrators to address all issues arising out of PC as well as user management.
- The main benefit that HP talks about in implementing PC is the centralized management of resources and creation of Performance CoE. Both benefits can be achieved without PC. A Performance CoE is not just standardization of processes. It also has other features such as knowledge management, research and development, technical competencies of the resources of CoE, metrics etc. PC is simply a cog in the complete machinery of CoE.
- The other benefit is the version control. Till PC 9.5, there was no version controlling in the scripts. But a work-around was there by keeping the script in separate project. However, for the scenario design version-control is zilch. A better version-control can be implemented at free-of-cost by using open source Subversion. Both scripts and scenarios can be version-controlled using Subversion and it gives a assurance on the scenario that gets executed. We simply have to create a new scenario from scratch in PC.
- Direct integration with QC. Yet this is not as important feature as it is made out to be. The principle reason is unlike QA (manual / automation) defects, pure performance defects are generally very less. So even if there is no direct integration with QC, defects can be easily tracked through QC.
- If there are specific settings that needs to be in load generators such as setting up the classpath for JAVA scripts, it still needs to be done manually by logging into the load generators. This follows my first point. PC is just a wrapper over LoadRunner.
- The other benefits of finding expensive performance bugs, improving response times are the benefits that LoadRunner already have.
- Implementation of standard processes to bring in efficiency is also touted as an additional benefit. However, performance testing starts with asking the right questions for requirement, architecture analysis, creation of test plans, monitoring strategy, etc. Performance Center can only help in listing out the requirements and execution of test. The rest loadrunner does it with or without performance center. Requirement gathering and test result analysis is still the tester’s job.
- Moreover, PC 11 claims to generate good reports. Unlike QC, where defect reports gives, good insights into overall testing status, performance report need quite a bit of human intervention. You really need an expert to provide meaning to the numbers and a proper conclusion which a tool can not achieve at this stage.
- Additionally LR Analysis is a great tool, and it works admirably well for collating and compiling the duration test results. PC simply fails to create analysis reports when the data is huge. Moreover downloading huge raw results, itself becomes a bottleneck during the analysis phase.
- Scripting still remains local and PC can do little in that.
- One advantage that PC has over LR is that all the stakeholders can view what is happening while the test is running. From a tester’s standpoint that is duplicity of efforts. Performance tester will be watching over the test plus the server health statistics to uncover potential performance bottlenecks. Management can at most say test is good or bad but still will have to wait till performance tester gives a thorough analysis of the test.
- Second advantage that PC can provide is when managing huge number of projects through a limited number of controllers and load-generators. However, this can be easily achieved using the Outlook calendar or even common excel that is shared. It doesn’t make a business sense to buy something expensive that can be achieved easily through an existing tool.
- Finally LoadRunner is a desktop application while PC is web application and web application can never be as fast as desktop applications. This is one huge disadvantage which PC cannot overcome.
So although on paper and in presentations, PC does look to be a great tool for top management, but when looked from ground-zero, it doesn’t match up to the expectations and a great many dollars can be saved by avoiding going for PC and sticking to LR itself. The point is if you already have paid for LR, there is no real business reason to go for PC.
So welcoming your thoughts and leaving with the following thought:(Image Courtesy)

Disclaimer: Author has worked till PC 9.5. Regarding PC 11.0 information has been collected from HP’s website.
Performance Testing in Agile Framework
Filed under: performance testing | Tags: agile, challenges in agile performance testing, performance testing, performance testing process, SLAs
Comments (5) 
This is again not a new thing in the industry. It has been there for some time now. However, recent initiatives within the organization where I work got me thinking. At the first look performance testing within Agile framework do not seem to fit in as performance testing for a large part has always been done within the functionally-stable-code paradigm.
On the other side performance testing at an early stage looks to be a very good idea. The reason is there will be limited possibility of presence hotspots in code-base. The main performance bottlenecks that may be present, would be more on the infrastructure side which are more easier to fix and with almost no functional regression-testing. Thus we do have a very good case for performance testing to be in Agile framework.
Although agile after each sprint delivers a workable product, there are some challenges that would crop-up here –
- Stakeholders Buy-in
- Project Management Vision
- Definition of the SLAs
- Unstable builds
- Development and Execution of Test Cases
- Highly skilled performance team
1. Stakeholders Buy-in
This is the most important aspect for any project. From a performance point of view this becomes altogether more important. Having an additional performance test team from the early phases of this project does put an additional strain on the budget and the timeline of the projects. Furthermore the advantages of performance testing are more of an intangible kind than say a functional testing. Thus it becomes a tad more difficult to get a stakeholders buy-in.
2. Project Management Vision
Despite the importance of the performance of an application, many project managers are still unaware of the performance test processes and the challenges a performance team faces. This apathy has been the undoing of many good projects. Within Agile framework, this would cause more conflicts between the project managers and performance teams. The ideal way would be to have a detailed meeting between the developers, performance architect/team and project managers and chalk out a plan which would decide the following –
- Modules to be targeted for performance testing
- Approach of performance testing
- In which sprint to begin of performance testing?
- Identification of Module-wise load that needs to be simulated
- Profiling Tool Selection
- Transition of Performance Tool – This would happen, as initially tools like JPerfUnit may be used and at a later stage end-to-end load testing tools like LoadRunner or SilkPerformer may be used.
These are some of the many parameters that needs to be defined at a project management level.
3. Definition of SLAs
This will be one of the most challenging aspect as business can always give an insight on end-to-end SLA. However, at a module-level it becomes more challenging. Here there arises the need for developer and performance architect to arrive at an estimated number. Apart from this, there may be a need for de-scoping of some modules as not all modules may be critical from performance stand-point.
4. Development and Execution of Test Cases
Although agile delivers a workable product at the end of every sprint, we may not be able to use the standard load testing tools as not all components would be present which a standard load-testing tool may require. So in most cases, there is an inherent challenge in simulating the load. Tools may very between phases. For instance, JPerfUnit, a stub or test harness might be used in the initial phases. An extra development time for this would have to be estimated in the initial project planning phase. Finally, once created, development and execution of test cases would follow. With the help of profiling tool, most performance hotspots can be identified early.
At later stages of the project, the traditional performance scripting and execution will replace the harness that was created in the earlier stage. So there will be a big re-work which again would be a challenge considering the sprint-timeline. So sprint should be planned taking this into consideration too.
5. Unstable builds
As development and testing is going on simultaneously, a break-off time would be needed within a sprint. The other alternative is to build the script on a continuous basis based which is quite difficult. Performance team would then create the required test script and test the code. This break-off point is only to enable performance team to work on a particular test case. If major changes occur after the break-off time, they will have to be incorporated in the next sprint.
6. High-skilled Performance Team
Last but not the least as the cliché goes. More than the skill-level, it is imperative that team members should have the confidence to get their hands dirty learning about the system and innovating as challenges continue to crop-up during the various sprints, keeping in mind the performance test approach, and thus ensuring a quality product.
The agile methodology does present lot of challenges at least from performance stand-point. However, if the performance angle is kept in mind from the beginning, it will certainly help in reducing lot of pain later. From a performance tester stand-point, agile is a gold-mine, as you get involved with developers at an early stage of the application. This would help in greater understanding of the application and its internal workings which eventually would help in better identification of performance bottlenecks.
So those are my ideas… Looking forward for your thoughts on this..
Why do performance testers need to know business?
Filed under: performance testing | Tags: business impact, performance testing, SLAs
Comments (2) 
Well the question does seem easy enough at the first look. This is what the managers across the board have been crying hoarse. Testers need to know business. Or else how can they test? Agreed. But when it comes to performance testers, does this hold good?
From a performance testing standpoint, what does a normal performance testers do? In almost all cases, the only way where the critical business flows are identified is via the hits on the web server. If it is a new application, most of the time, the business will have a fair idea of which flows will be critical and those will be handed down to the performance testers.
Now our performance tester will come in and write scripts, designs the scenario based on the requirements and executes the test. During the analysis, the following things will be looked at.
1. Server Health
2. Performance issues in code
3. SLAs
So keeping this in mind where does the business come in? Does it really matter to the performance tester to understand the business? The only that matters to him is whether the SLA has been achieved or if there are some hidden performance bugs which may crop up apart from the server health. Everything related to do with the technology and almost nothing with business except the SLAs, if there are any. Experienced performance testers, do not even need to see the flow and they can make the script robust. On the other hand a functional tester cannot do without knowing the business, with the automation engineer falling somewhere in between these two extremes. Is this the correct way of looking at it?
Now coming to the answer to the question in the title of the post. Every business for its survival have to create a positive impression on its customers/clients. Any customer who interacts via a business transaction takes with him/her an experience. And this experience is what makes the customer comes back again and again building a relationship with the business. Out in a retail shop, businesses control this by having good sales force, good ambience, etc. However, online the only experience that a user can get is the look and feel of the application, ease of traversing and the speed with which the customer’s job is done. Thus performance testers directly impact the bottom-line of the business as they are responsible for this user experience. Thus it becomes imperative for performance testers to know the business, from where the revenue comes to ensure the application creates a good user experience which in turn helps the business to grow!
PS: The other testing is also equally important. However, I just wanted to bring out the importance of a business knowledge for performance testers and their impact on business which is much more than what most performance testers tend to believe.
Its a developer’s world!
Filed under: Uncategorized | Tags: developer's world, idea, performance testing, software testing, testing
Comments (2) Being a tester, I should be trying to bust that myth. Yet, here I am endorsing that view. It is an irony. But this is the truth.
The world of software has come a full cycle. It started with only developers who wrote abstruse code. Then testers came into the picture. Their job was to break it and they were getting paid for that. They were absolved from all responsibilities of understanding the code beneath. They were only concerned about the functionality.
With the fast paced changing of the business and the rise of internet, their arose the problem of increased number of users and thus the performance of applications became a determining factor in the success of the business. Thousands of users accessing the application around the same time broke the servers. And so the performance testers were born. Yet in all these cycles, one thing remained the same – Only developers would look at the code and testers will ignore the code. Even the unit testing was supposed to be done by the developers and the testing will be done by independent testers. This was to remove the my-code bias they said. All true. But the adage remained –
Testers would not look into the code beneath.
Some claimed the world is changing. The testers will be the new lord of the software world as more applications will go in maintenance mode. But technologies evolve faster than a single cell amoeba. The developer remained the king. The testers became the judiciary, holding aloft the high ground of ensuring the business functionality is as per the requirements.

However, today testers are getting challenged. This time it is not the old rival – the developers. But technology itself on which they worked. Instead of the straight-forward, three tier architecture, the architecture moved to n-tiered architecture, involving newer design principles. The first technology that challenged testers was the Service Oriented Architecture (SOA).
Suddenly the familiar UI, which was the tester’s playground, was robbed from them. They were asked to test a non-UI functionality. SOA was sacrilege for a tester’s religion revolved around UI. Now it is the norm. With host of new middlewares coming, each of them non-UI, the testers have lost their favorite playground.
The MQs, JMS, and the webMethods of the world have asked a new question to all the testers. How are you going to test? How will you break the code, without knowing the newer technologies? What testing can be done to ensure these middlewares are functioning as designed?
To answer these questions, testers need to abolish the old adage. They not only have to look into the code, but they have to understand it and then write code themselves which will try to break the developer’s code. A big challenge for a tester is the shrinking testing time in SDLC. Yep that is why, the business do not want a tester who knows only business and write test cases around. Organizations want a person who not only understands business and but can write codes to break the code. A person in whom both technical and business skills are in yin-yang balance. That points to a developer with business understanding.
So testers – to save your jobs, become the next generation developers. Alright, that is a bit over the board 🙂 . Yet the essence of the post is brush up your coding skills – your next project may just need it.
PS: Just to be on a technically correct side, testers these days need to know the language in which the code was developed, may have to write wrapper codes which would give interface like features. Of course, there still exists UI-based testing, yet organizations depend on automation to get the UI testing done. What they want testers from testers is innovative test strategies which can efficiently test the mix of old and new technologies, independent of the developers. A big challenge, yet an achievable one like all other challenges.. 🙂
P.PS: I have taken the liberty of taking some assumptions in this post to emphasize my point. So your comments are most welcome.
Performance Testing Myths
Filed under: performance testing | Tags: myths of performance testing, performance testing
Comments (3) I had started the blog with every intention to post more regularly. However, I am not been able to do so for reasons galore. Anyways here I bring bust some of the myths that surround performance testing as a practice.
Myth #1
Performance Testing is done to break the system just as functional testing is done to break the code.
Performance testing is not done to break the system. The principle objective of performance testing is to get an insight as to how an application would behave when it would go live. Thus breaking the system is not the objective. However, we would sometimes definitely want to know the point beyond which the system would crash. This is stress testing aspect of performance testing and not the entire performance testing. Performance testing consists of various types of test. Some of the examples are Load Testing, Stress Testing and Endurance Testing. Each of the tests are conducted with a specific objective in mind. Thus not all tests are done for all the projects. But they included as per the requirements of each of the projects.
Myth #2
Performance Testing is all about scripting.
This I have discussed in my last post. You can check it out here
Myth #3
Performance Testing is a line extension of functional testing.
This is a very popular myth among many of the functional testers. The myth has its origin in the evolution of testing practice as a whole. Initially all the testing which was executed manually. Then tools were created to automate the tools and thus the automation testers came in place. Extending this thought process to performance testing, it is widely believed that performance testing is just learning another tool and some definitions like hits/sec and throughput. Another place from where the myth is permeated is when most of the test managers view performance testing through the lens of functional testing. This creates problem conducting a performance test projects as all the metrics then collected would have been defined through the lens of functional testing. Test metrics applicable to functional and automation testing are to measure performance testing as well.
For example a dry run of automation scripts is done to get some very obvious bugs. However a dry run of performance test scripts is done to ensure the scripts created are robust and would not fail when an actual test execution is performed.
Myth #4
The results that are true for a single server can be simply extrapolated to 2 or more servers in production.
Scenario – The client – I have a single server for doing performance testing but in production there will be 4 servers. So we can simply take the test results and extrapolate to get the result for the 4 servers. Any performance test engineer would never back his results against extrapolation. The reason – The moment an environment different from PT environment comes, the number of variables that get introduced in the equations would increase and thus would throw our results out of the window.
Simply put, even after 100 years of research in understanding weather patterns, we still are unable to figure out whether there will be drought or flood next year. You can argue that we can at least predict weather for the current day. Well, that bit we can do with performance testing as well.
Well that’s all I have got. Do drop in other myths that you may have experienced to make this list more comprehensive. Till then cya 🙂
It is not all about scripting, honey!
This will be my first post where I will be writing about what actually I do. Performance testing (PT) being a very niche field, very little information is available on it, so I thought of explaining some of the basic concepts of performance testing.
PT really came into picture from the time when the client-server architecture came into being. For all the desktop applications, performance testing was not much needed as only a single user is going to access at a time and so it makes very little difference in performance. However, in web-based applications, the number of clients hitting the server started becoming large. This brought the performance testing into limelight as most application owners were never sure if the servers could support the large number of users.
Any type of testing is a mitigation of risk. Performance testing helps the application owners understand how the application would behave in the actual production environment by simulating the real-time behavior of the actual users on the application. Thus performance testing would mitigate the risk of application crashing or becoming very slow in giving responses to the client requests.
So am done with definition. The highlighted words explain the entire spectrum of activities that are involved in performance testing. That simple performance testing is. 😉
-
Simulating Real-Time behavior of actual users on the application
-
Application behavior in the actual production environment
I have added a mind-map on performance testing. This is the first time I am using it. So forgive me if I have messed it up. 🙂

Simulating Real-Time behavior of actual users on the application (Two parts to this statement too. 🙂 )
Real-Time behavior of the Users on the application
This is the most important part as this becomes the starting point of performance testing process. We need to understand how the actual users are going to hit the application. Some of the basic questions are like how many users are going to hit the application at the same time. Which are the actions that the most users are likely to do it most of the time? This is important as for a web-based email application like Yahoo mail, most users are likely to login and click on inbox. A minuscule of people will probably change their account settings. So here the checking of inbox becomes a critical action as most people are going to perform this action and the performance of this action can affect the number of users using yahoo mail.
Simulating
The simulation of the number of users is done through the use of various performance testing tools like LoadRunner, SilkPerformer, Jmeter, OpenSta. The checking of the mail action is recorded with the help of these PT tools. This process is the scripting process. Finally the expected number of users performing the inbox checking action at definite rate is simulated. This is in PT jargon called the Test Execution.
Application behavior in the actual production environment
While the simulation is going on, we will be monitoring various important health-parameters of the servers involved like the application servers, the web servers and the database servers. Once the test execution is completed, the behvior of the application under simulated condition is analyzed and a report is submitted on the appication’s behavior under the expected user load.
So thats it all the major concepts of performance testing is covered. Well as you can see the Scripting per se plays very little role in the entire PT process. The reason it has larger than life role is that it consumes the highest amount of time of all the activities and so eats up most of the billing. But unless other activities are not understood, the entire purpose of performance testing is defeated.
PS: The major motivation for writing the post is to create an awareness about PT at least among those who are interested in learning performance testing tools. Also to make them understand that the learning the tool is not the end in itself. It is a small but important step to understand what performance testing really is. You can always bug me on this as i am always glad to help on this topic 😉 hehehe
P.PS: For others, hopefully I have not caused any emotional atyachar on you people. 😀
